Part 2:
Multimodal Prototyping!
In Part 1 of this piece I outlined the history of voice technology, the state of the market today and possible future developments. I also covered design considerations for VUI. After carrying out this research, I began to think about ways I might truly harness it and undertake a practical prototyping exercise, as this could be a really interesting way to understand the particular challenges encountered when designing for voice.
I gathered the Ostmodern Product Design team together and presented my findings, whilst simultaneously asking them to think about previous projects they had undertaken and where they thought voice technology could have provided solutions to design challenges.
After collating responses, I looked for an idea or combination of ideas that I could use as a basis for the prototype I was going to build (I refer here to the ‘Wizard of Oz’ test that I described in Part 1). I wanted to strike a balance between simple and achievable yet complicated enough to provide interesting avenues to consider. As this was an exploratory exercise, at the time the rest of the plan remained flexible and based on my experience trusted that additional aspects these would reveal themselves as the process went on.
One of the ideas that was formulated during the Ostmodern workshop related to the use of a conversational interface for the purpose of content discovery within a film/TV streaming product. I believed that the idea of mapping out a variety of different conversations that a user might have when trying to find something to watch was interesting, so I adapted it into the form of a conversational discovery tool for Netflix, a streaming platform that most test participants were likely to be familiar with.
One theme that came up more than once when researching ideas about future trends in the VUI space was that of multimodal design. As devices like the Amazon Echo Show (a smart speaker with a screen, launched in 2017) become more popular greater consideration will be required to successfully align design approaches for the combined use of screen and voice, and there will be countless opportunities that this combination can offer that individually they do not.
As I mentioned in Part 1, the Wizard of Oz testing method is a way of quickly iterating on a script for a VUI. While going through this process for this project and tool idea would undoubtedly be interesting, I started to wonder about the possibility of creating some sort of multimodal prototype, where phrases uttered by the computer are combined with wireframes. Before I could assess whether this would be possible I needed to understand the boundaries of the situation I was designing for and start to map out the conversational portion of the prototype.
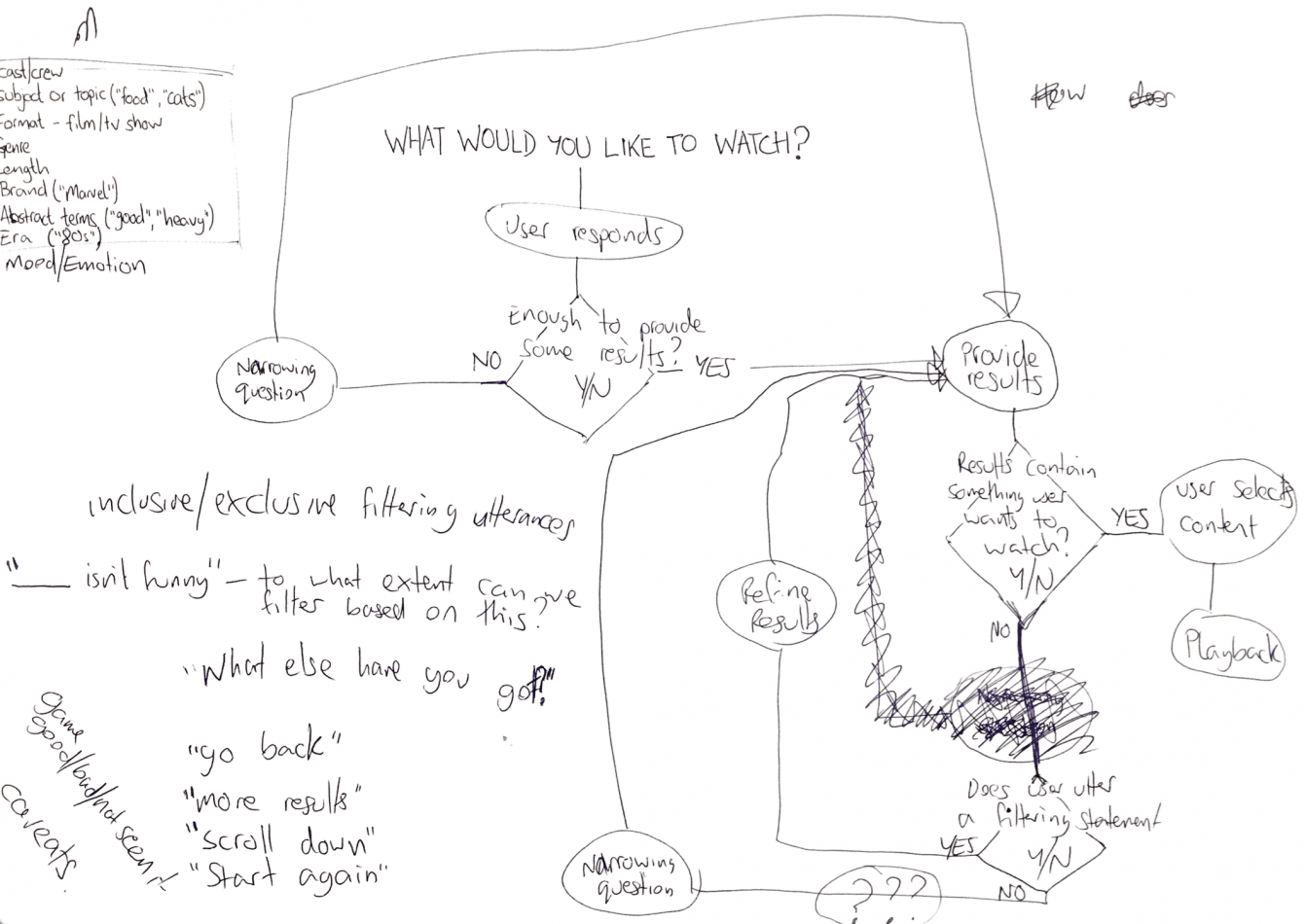
Using the whiteboard, I tried to consider as many facets of the problem as possible and plot a journey. My thoughts focused on the following - what are the potential constants and variables when interacting with a tool of this type? Once I had done this, I started to think about what users think about and how they would respond when asked what they want to watch. These utterances could vary greatly in how specific they are, from asking for a particular piece of content through to “I don’t know!” I started to conceptualise this process as a kind of funnel, zeroing in on a selection of results that the user could choose from. I split the utterances into those which might be specific enough to display some results and those which aren't and therefore need the VUI to ask follow up questions to get to that point.

Mapping out the conversation parameters on the whiteboard
Next I started to consider the idea of a multimodal prototype. My first thought for achieving this was to combine Ben Sauer’s Say Wizard tool mentioned in Part 1 with some wireframes contained in a Keynote presentation. It was however likely that this could end up clunky and slow, with pauses while the tester searched first for the appropriate phrase to trigger and then for the correct wireframe to accompany it. What we really needed was a way of triggering both the phrase and the wireframe with the same event (key press, mouse click etc.), but I was unaware of any prototyping software that offered this functionality. Until the lightbulb moment came…
Max
Max is a visual programming language developed by Cycling 74, whose tagline as a company is “tools for sound, graphics, and interactivity”. As a musician with a love of composing and producing electronic music in my spare time, I had been teaching myself Max in the few months preceding this research project. It took a little bit of time for the penny to drop, but then it finally occurred to me that Max was the answer. The “sound, graphics and interactivity” stated in the tag line would refer to the phrases uttered by the computer, the wireframes, and the triggering of these in response to the user respectively. I could construct my multimodal prototype in Max!
As a bit more background for those not familiar with Max, a file is called a ‘patch’. Patches are created by connecting objects together with little virtual wires. There are hundreds of different objects each with their own set of functions, so what objects you use and how you connect them together determines the behaviour of the patch. While the intricacies of programming in Max are beyond the scope of this piece, the possibilities are limitless and I was sure I could achieve the results required to deliver the project. This also prompted an interesting question - as a UX designer, is Max a practical environment for creating a prototype? Depending on the complexity of the patch, it could take a considerable amount of time to put the prototype together, which would not necessarily be conducive to rapid testing and iterating. At this point I decided to keep scalability and reusability in the back of my mind as I proceeded.
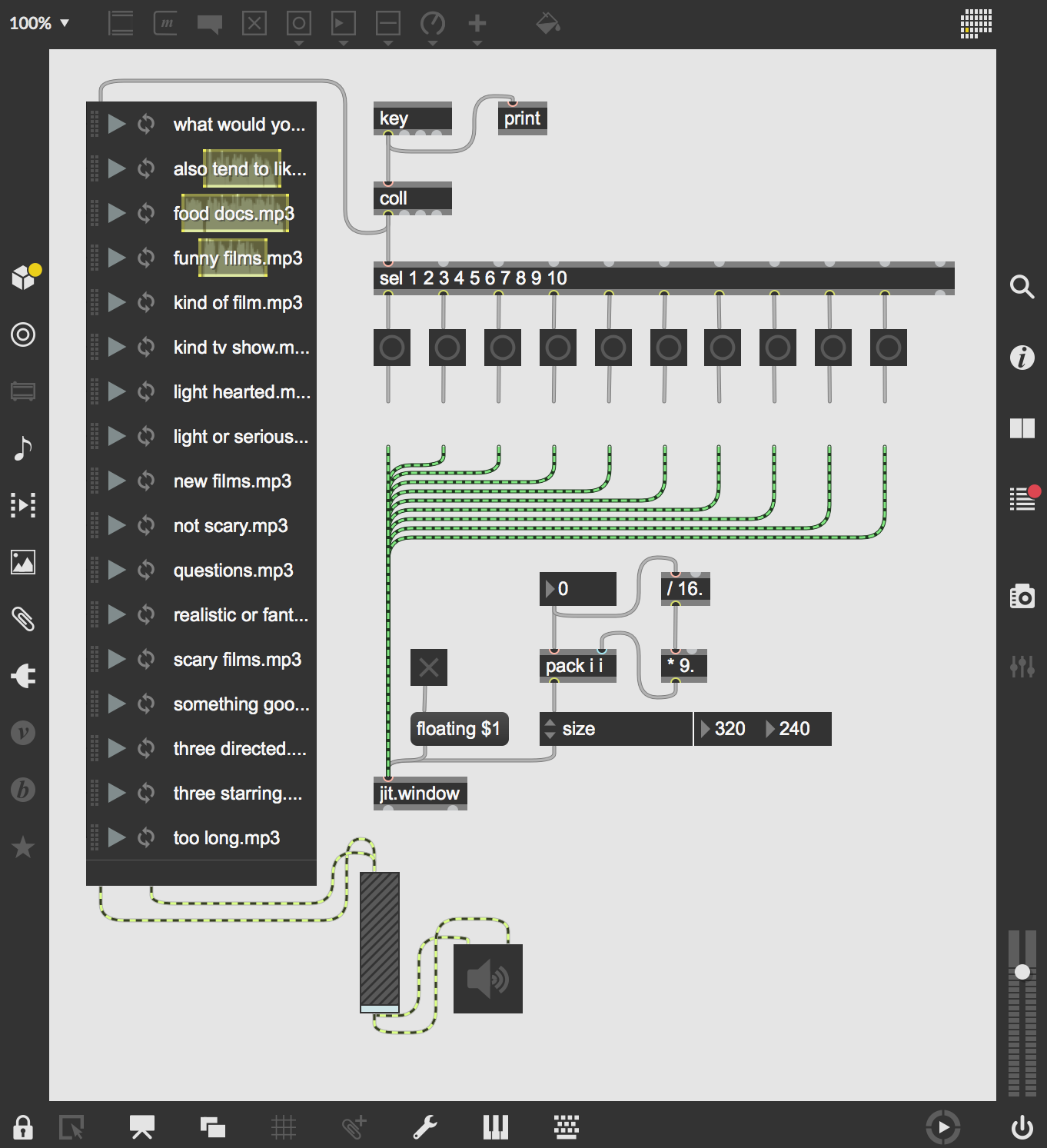
This image shows the first iteration of the prototype. The patch takes the keyboard input and triggers both a recorded phrase and an image at the same time. The concept worked, so it gave me the green light to pursue this as a viable option.
And then I went off the deep end.
The thing is, when working in an environment with endless possibilities, each successfully implemented action sparks off more ideas, together with the desire to realise them. Ok, so I can trigger sounds… how about making it interface with the computer’s text to speech software to make adapting the script more streamlined? As this is a TV prototype, should I introduce remote control input? How about a home screen with a long button press to activate the smart assistant? Wait now, how about creating selected states for the remote control presses?! Ooo what about a way of logging the remote button presses so they can be analysed later?!! You get the picture. However, as this was an exploratory piece, I knew it was important to try each of these ideas out to see where they led. I knew some might end up being fruitless, but that was part of the learning experience!
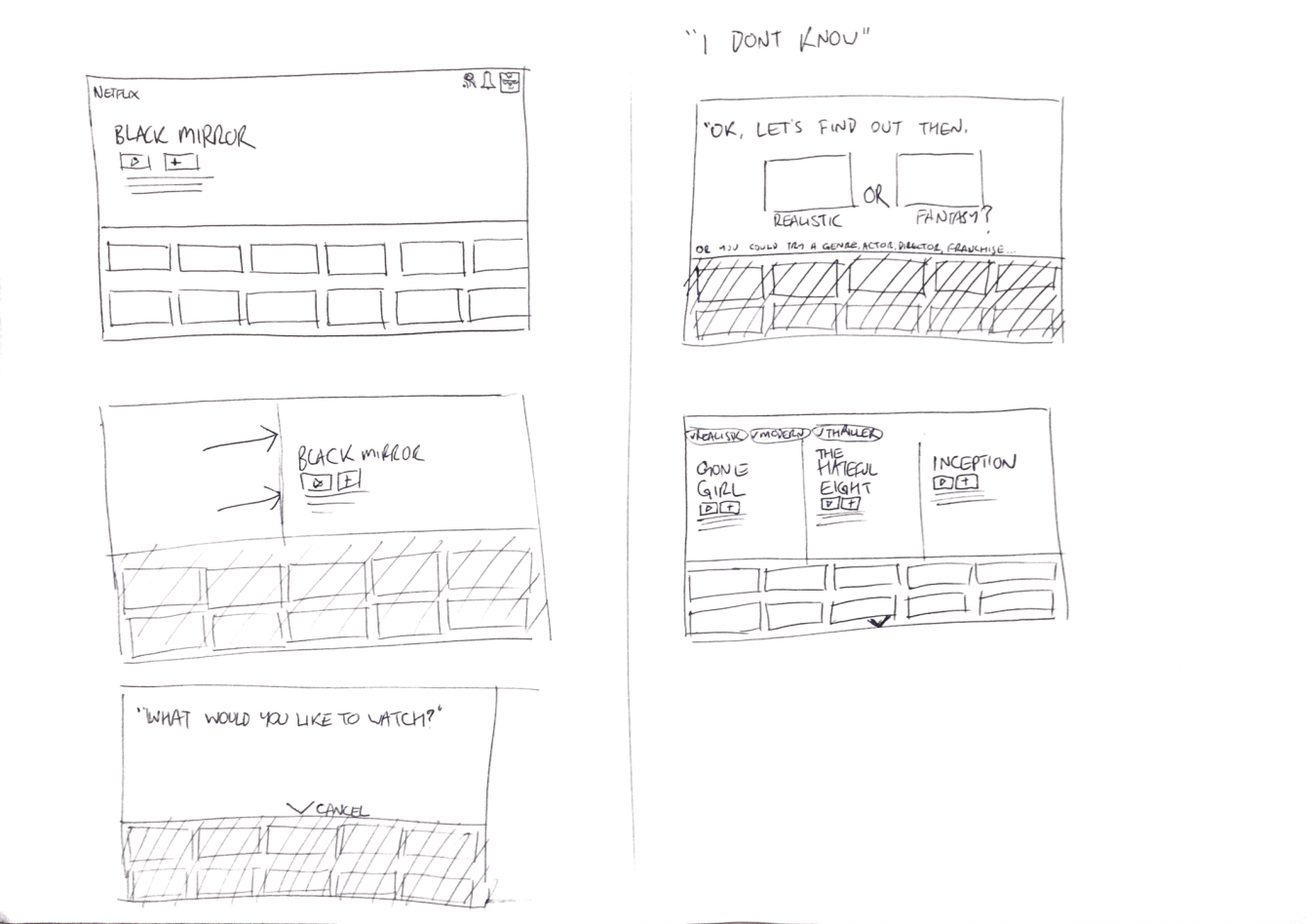
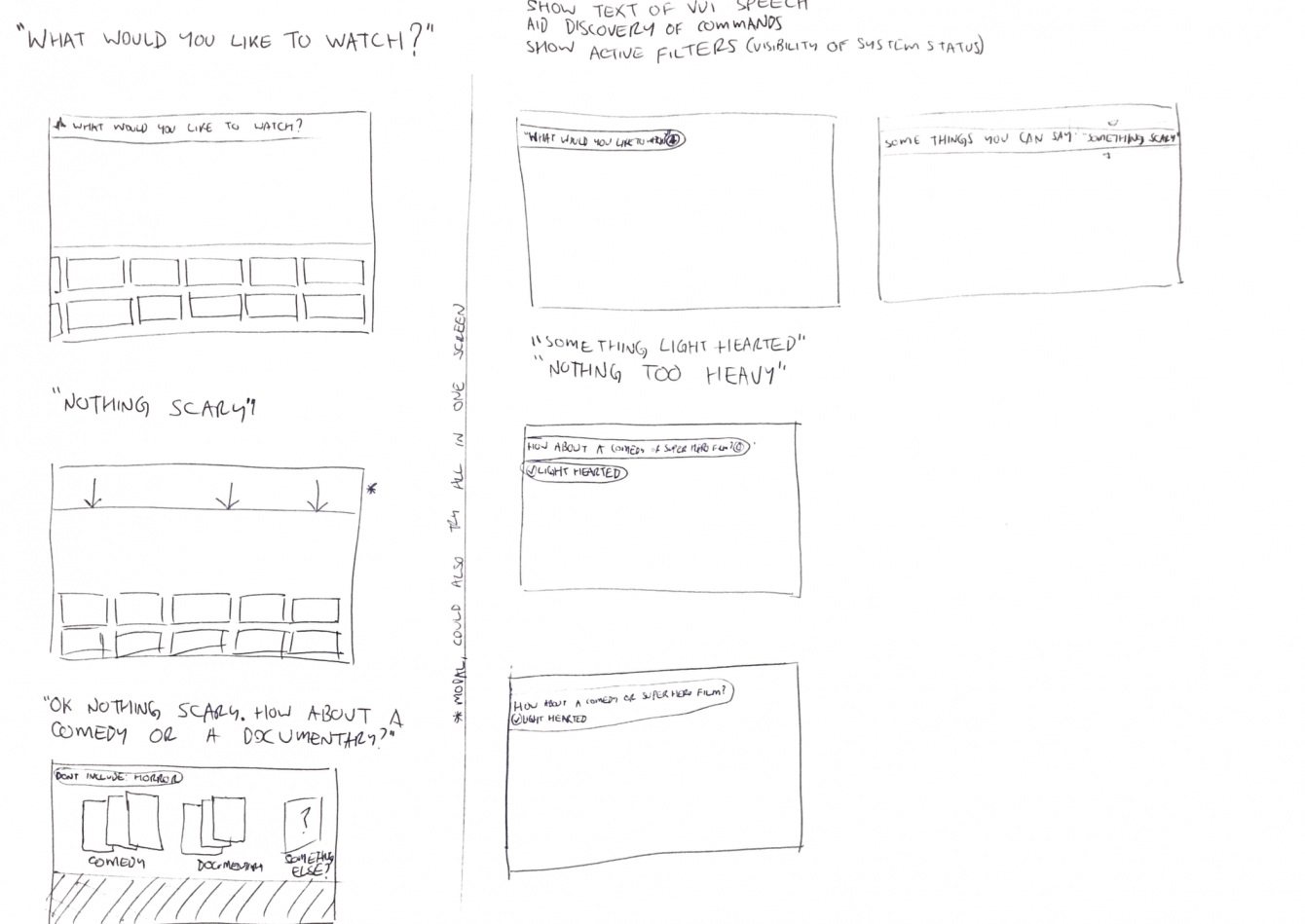
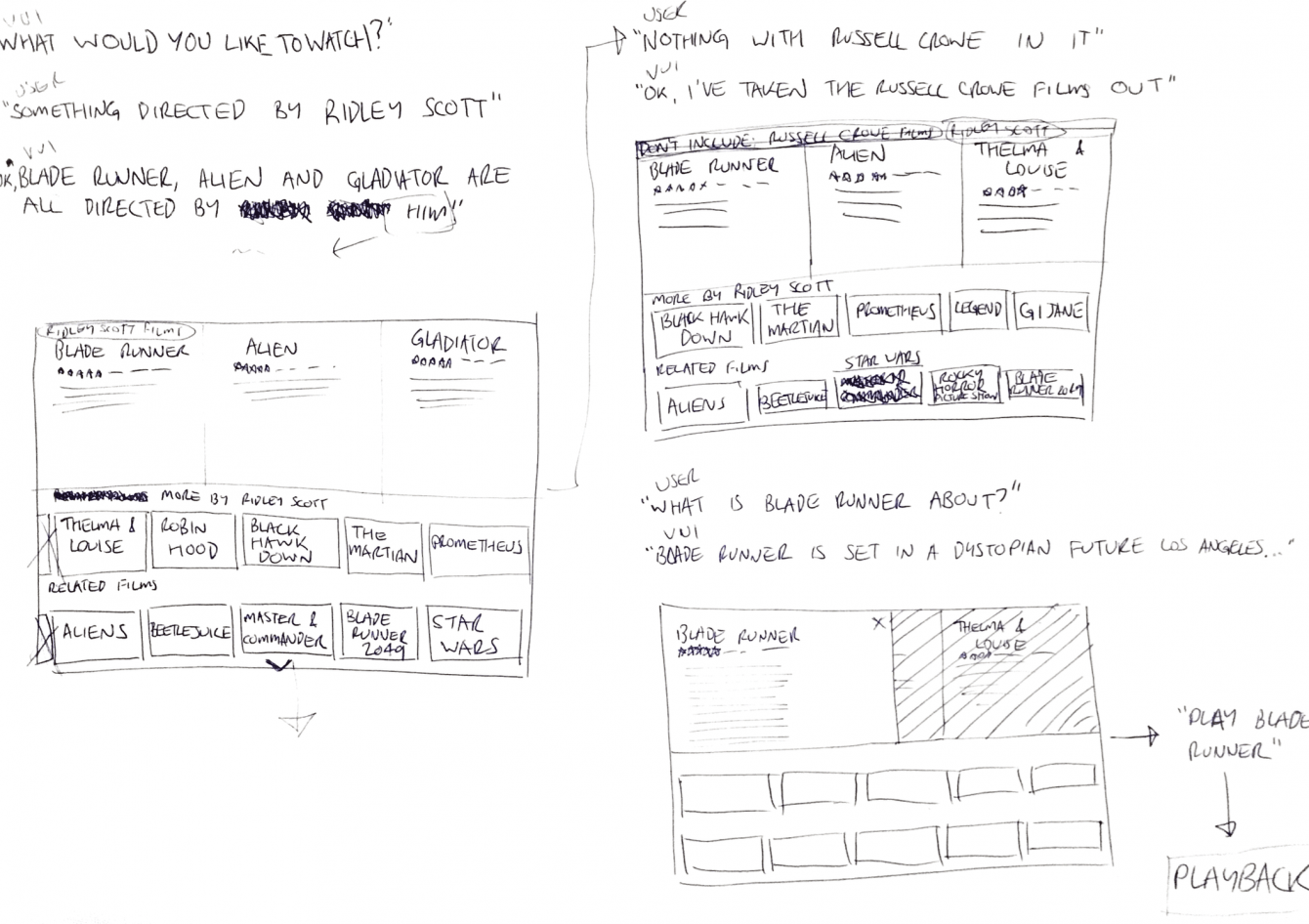
Some (very) rough early sketches of the GUI
Testing
After hand sketching some screen ideas, I talked them through with our talented UI designer, Josh. He come back to me with some padded out digital designs and I was then able to slot them into the prototype and start my testing! Working with Anna in the research team, together we undertook 7 user tests with our colleagues. These took the form of an interview to get some insight on their levels of experience with and expectations of voice technology, followed by interaction with the prototype. The results uncovered a plethora of insights. Some highlights are below:
- Users vary an awful lot in their experience and expectations of voice technology
- They would not necessarily expect to use voice to discover new content in a conversational manner, so this would have to be established and trust built
- Populating wireframes with content can be time consuming but adds a level of immersion that is important - stick with the most popular genres/titles
- If there are multiple control methods present (e.g. voice and remote control) then make it clear so that the user knows when they can use either via selected states or animations that confirm that the system is engaged and listening.

The other really interesting part of this project was the process of building the prototype itself and assessing Max’s abilities as a tool for this purpose. Some of these learnings included:
Pros
- As far as I am aware, this method of designing a multimodal voice/visual prototype is totally unique (I am of course interested in hearing from you if you disagree!)
- Max is incredibly flexible and there are endless possibilities when building a prototype
- Due to the programme’s acceptance of remote control input there are potentially a lot of interesting interaction options available
- The prototype is able to achieve a high level of fidelity
Cons
- More sophisticated visual transitions between screens are not feasible at this time
- Elements like selected states and page scrolling are difficult to achieve
- Pretty ‘hacky' - due to the complex nature bugs appear fairly often and can be difficult to troubleshoot in the middle of a test

The finished prototype behind the scenes (told you I went off the deep end!)
Coming back to the idea of reusability and scalability, I was able to make a blank template version of the prototype for use with future projects. This version accepts a text file of the voice script (in the same manner as Say Wizard) to make inputting the phrases quick and easy. The wireframes can also be dragged and dropped into place which means that in theory a multimodal testing session could be established relatively quickly, and that is perfect for rapid iteration.
To conclude, voice technology has arrived and is only going to get more popular. This project was a great opportunity to get under the skin of the design process for voice and to explore some of the subtleties of how voice and visuals are affected when they collide. Max is also an interesting option when prototyping for the combination of these two mediums. I’m excited to see how this develops in the future and hope to be a part of it.